Data formats¶
Prosodylab-aligner format¶
Every .wav sound file you are aligning must have a corresponding .lab
file containing the text transcription of that .wav file. The .wav and
.lab files must have the same name. For example, if you have givrep_1027_2_1.wav,
its transcription should be in givrep_1027_2_1.lab (which is just a
text file with the .lab extension).
Note
If you have transcriptions in a tab-separated text file (or an Excel file, which can be saved as one), you can generate .lab files from it using the relabel function of relabel_clean.py. The relabel_clean.py script is currently in the prosodylab.alignertools repository on GitHub.
If no .lab file is found, then the aligner will look for any matching .txt files and use those.
In terms of directory structure, the default configuration assumes that files are separated into subdirectories based on their speaker (with one speaker per file).
An alternative way to specify which speaker says which
segment is to use the -s flag with some number of characters of the file name as the speaker identifier.
The output from aligning this format of data will be TextGrids that have a tier for words and a tier for phones.
TextGrid format¶
The other main format that is supported is long sound files accompanied by TextGrids that specify orthographic transcriptions for short intervals of speech.
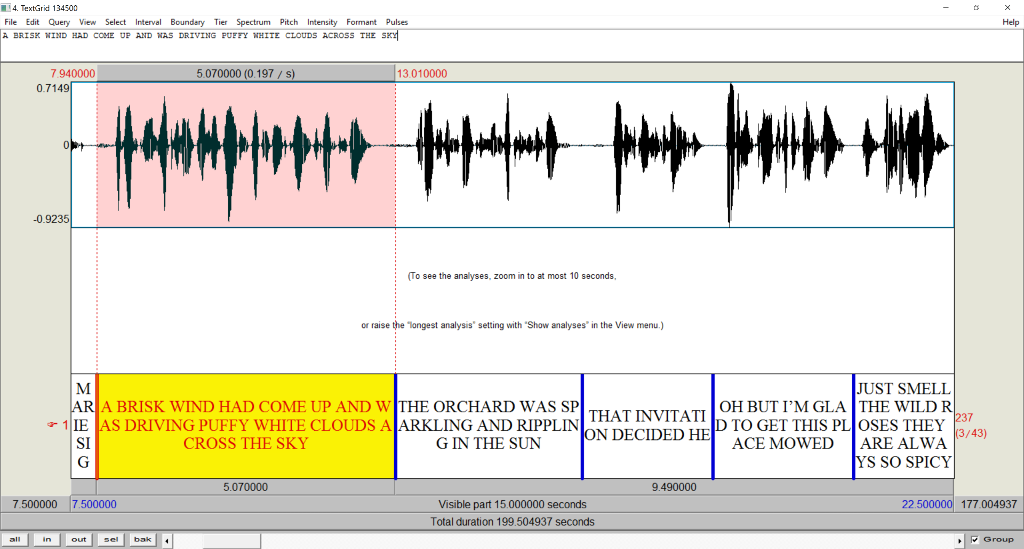
If the -s flag is specified, the tier names will not be used as speaker names, and instead the first X characters
specified by the flag will be used as the speaker name.
By default, each tier corresponds to a speaker (speaker “237” in the above example), so it is possible to align speech for multiple speakers per sound file using this format.
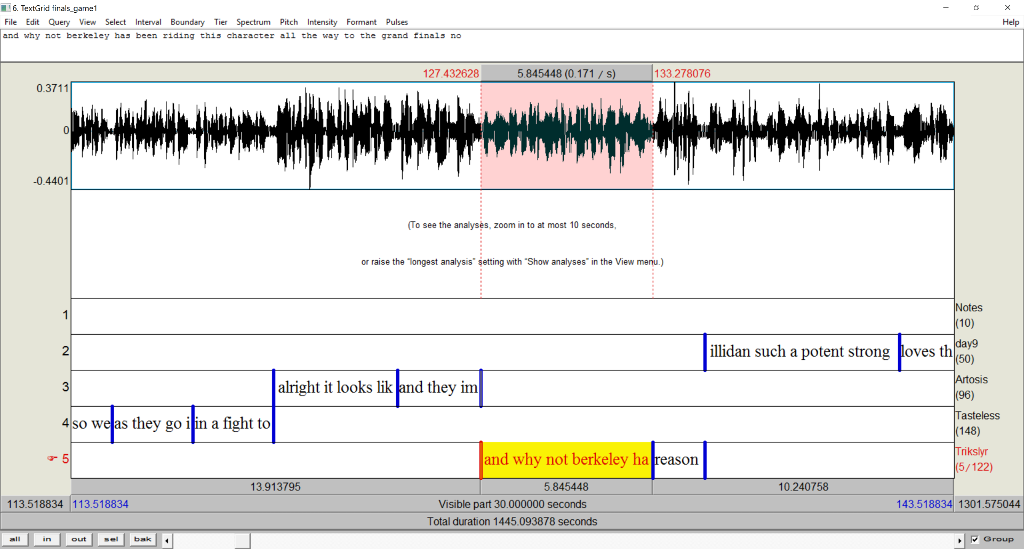
Stereo files are supported as well, where it assumes that if there are multiple talkers, the first half of speaker tiers are associated with the first channel, and the second half of speaker tiers are associated with the second channel.
The output from aligning will be a TextGrid with word and phone tiers for each speaker.
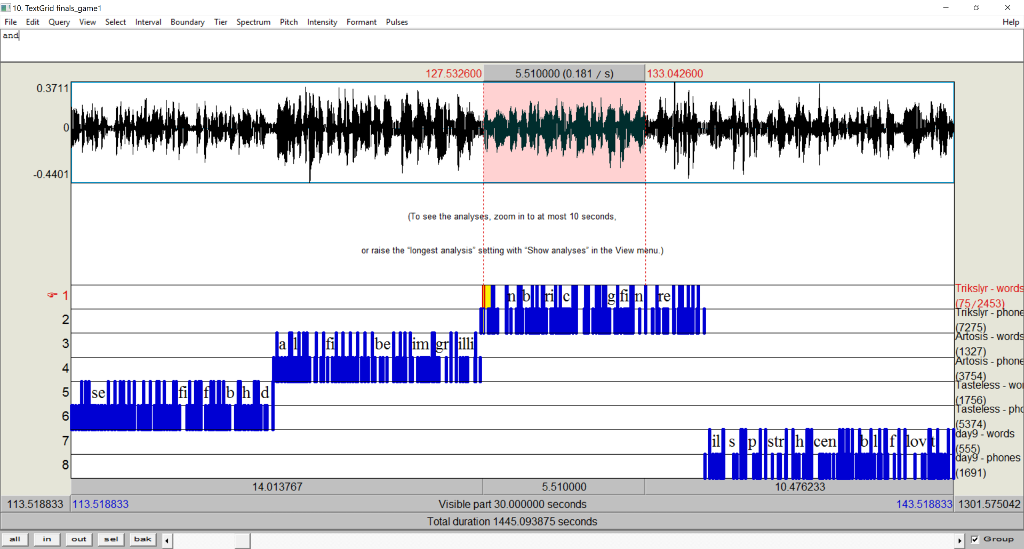
Note
Intervals in the TextGrid less than 100 milliseconds will not be aligned.
Transcription normalization and dictionary lookup¶
If a word is not found in the dictionary, and has no orthographic markers for morpheme boundaries (apostrophes or hyphens), then it will be replaced in the output with ‘<unk>’ for unknown word.
Note
The list of all unknown words (out of vocabulary words; OOV words) will
be output to a file named oovs_found.txt
in the output directory, if you would like to add them to the dictionary
you are using. To help find any typos in transcriptions, a file named
utterance_oovs.txt will be put in the output directory and will list
the unknown words per utterance.
As part of parsing orthographic transcriptions, punctuation is stripped from the ends of words. In addition, all words are converted to lowercase so that dictionary lookup is not case-sensitive.
Dictionary lookup will attempt to generate the most maximal coverage of novel forms if they use some overt morpheme boundary in the orthography.
For instance, in French, clitics are marked using apostrophes between the bound clitic and the stem. Thus given a dictionary like:
c'est S E
c S E
c' S
etait E T E
un A N
And two example orthographic transcriptions:
c'est un c
c'etait un c
The normalization would result in the following:
c'est un c
c' était un c
With a pronunciation of:
S E A N S E
S E T E A N S E
The key point to note is that the pronunciation of the clitic c' is S
and the pronunciation of the letter c in French is S A.
The algorithm will try to associate the apostrophe with either the element before (as for French clitics) or the element after (as for English clitics like the possessive marker).
Hyphens are treated the same as apostrophes. For example, merry-go-round will
become merry go round if the hyphenated form is not in the dictionary.
If no words are found on splitting the word based on hyphens or apostrophes,
then the word will be treated as a single unit (single unknown word).