Corpus formats and structure#
Prior to running the aligner, make sure the following are set up:
A pronunciation dictionary for your language should specify the pronunciations of orthographic transcriptions.
The sound files to align.
Orthographic annotations in .lab files for individual sound files (Prosodylab-aligner format) or in TextGrid intervals for longer sound files (TextGrid format).
Note
A collection of preprocessing scripts to get various corpora of other formats is available in the MFA-reorganization-scripts repository and @mmcauliffe’s corpus creation scripts.
Specifying speakers#
The sound files and the orthographic annotations should be contained in one directory structured as follows:
+-- textgrid_corpus_directory
| --- recording1.wav
| --- recording1.TextGrid
| --- recording2.wav
| --- recording2.TextGrid
| --- ...
+-- prosodylab_corpus_directory
| +-- speaker1
| --- recording1.wav
| --- recording1.lab
| --- recording2.wav
| --- recording2.lab
| +-- speaker2
| --- recording3.wav
| --- recording3.lab
| --- ...
Using --speaker_characters flag#
Warning
In general I would not recommend using this flag and instead sticking to the default behavior of per-speaker directories for Prosodylab-aligner format and per-speaker tiers for TextGrid format.
MFA also has limited support for a flat structure directory structure where speaker information is encoded in the file like:
+-- prosodylab_corpus_directory
| --- speaker1_recording1.wav
| --- speaker1_recording1.lab
| --- speaker1_recording2.wav
| --- speaker1_recording2.lab
| --- speaker2_recording3.wav
| --- speaker2_recording3.lab
| --- ...
By specifying --speaker_characters 8, then the above files will be assigned “speaker1” and “speaker2” as their speakers from the first 8 characters of their file name. Note that because this is dependent on the number of initial characters, if your speaker codes have varying lengths, then it will not behave correctly.
For historical reasons, MFA also supports reading speaker information from files like the following:
+-- prosodylab_corpus_directory
| --- experiment1_speaker1_recording1.wav
| --- experiment1_speaker1_recording1.lab
| --- experiment1_speaker1_recording2.wav
| --- experiment1_speaker1_recording2.lab
| --- experiment1_speaker2_recording3.wav
| --- experiment1_speaker2_recording3.lab
| --- ...
By specifying --speaker_characters prosodylab, then the above files will be assigned “speaker1” and “speaker2” from the second element when splitting by underscores in the file name.
Using --single_speaker flag#
MFA uses multiple jobs to process utterances in parallel. The default setup assigns utterances to jobs based on speakers, so all utterances from speaker1 would be assigned to Job 1, all utterances from speaker2 would be assigned to Job 2, and so on. However, if there is only one speaker in the corpus (say if you’re generating alignments for a Text-to-Speech corpus), then all files would be assigned to Job 1 and only one process would be used. By using the --single_speaker flag, MFA will distribute utterances across jobs equally and it will skip any speaker adaptation steps.
Transcription file formats#
In addition to the sections below about file format, see Text normalization and dictionary lookup for details on how the transcription text is normalized for dictionary look up, and Dictionary and text parsing options for how this normalization can be customized.
Prosodylab-aligner format#
Every audio file you are aligning must have a corresponding .lab
file containing the text transcription of that audio file. The audio and
transcription files must have the same name. For example, if you have givrep_1027_2_1.wav,
its transcription should be in givrep_1027_2_1.lab (which is just a
text file with the .lab extension).
Note
If you have transcriptions in a tab-separated text file (or an Excel file, which can be saved as one), you can generate .lab files from it using the relabel function of relabel_clean.py. The relabel_clean.py script is currently in the prosodylab.alignertools repository on GitHub.
If no .lab file is found, then the aligner will look for any matching .txt files and use those.
In terms of directory structure, the default configuration assumes that files are separated into subdirectories based on their speaker (with one speaker per file).
An alternative way to specify which speaker says which segment is to Using --speaker_characters flag with some number of characters of the file name as the speaker identifier.
The output from aligning this format of data will be TextGrids that have a tier for words and a tier for phones.
TextGrid format#
The other main format that is supported is long sound files accompanied by TextGrids that specify orthographic transcriptions for short intervals of speech.
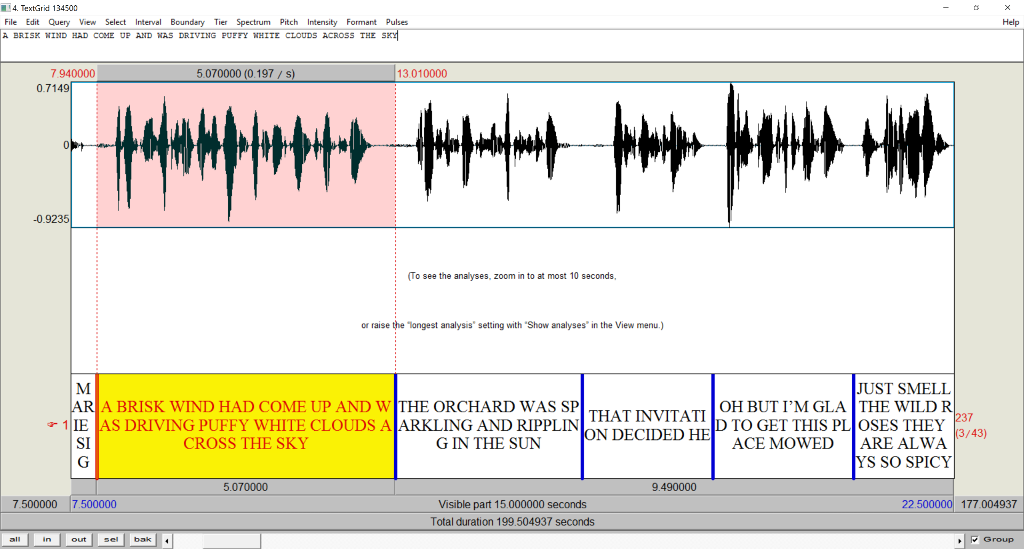
If Using --speaker_characters flag, the tier names will not be used as speaker names, and instead the first X characters specified by the flag will be used as the speaker name.
By default, each tier corresponds to a speaker (speaker “237” in the above example), so it is possible to align speech for multiple speakers per sound file using this format.
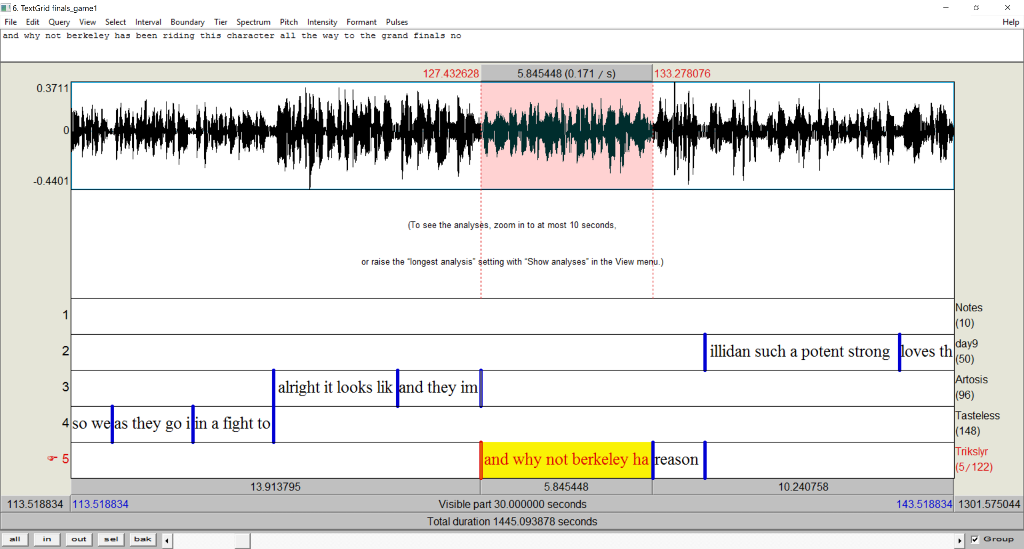
Stereo files are supported as well, where it assumes that if there are multiple talkers, the first half of speaker tiers are associated with the first channel, and the second half of speaker tiers are associated with the second channel.
The output from aligning will be a TextGrid with word and phone tiers for each speaker.
Note
Intervals in the TextGrid less than 100 milliseconds will not be aligned.
Including reference alignments#
As of version 3.3, it’s possible to use reference alignments that have been hand corrected or verified to guide training
or adaptation of acoustic models. The two ways to specify reference alignments, either in the corpus files or supplied via
a --reference_directory argument supplied to Train a new acoustic model (mfa train) or Adapt acoustic model to new data (mfa adapt). In both cases,
MFA will use a tier named like {speaker_name} - phones (i.e., the same format as MFA’s TextGrid output). MFA will also
load intervals from {speaker_name} - words as reference words, but these are not actually used or necessary, as all alignments
are on a phone basis.
Note
You can use MFA’s Anchor Annotator to more easily fix and save manual alignments for use in MFA training.
Sound files#
The default format for sound files in Kaldi is .wav. However, if MFA is installed via conda, you should have sox and/or ffmpeg available which will pipe sound files of various formats to Kaldi in wav format. Running sox by itself will a list of formats that it supports. Of interest to speech researchers, the version on conda-forge supports non-standard wav formats, aiff, flac, ogg, and vorbis.
Note
.mp3 files on Windows are converted to wav via ffmpeg rather than sox.
Likewise, opus files can be processed using ffmpeg on all platforms
Note that formats other than .wav have extra processing to convert them to .wav format before processing, particularly on Windows where ffmpeg is relied upon over sox. See Convert to basic wav files for more details.
Sampling rate#
Feature generation for MFA uses a consistent frequency range (20-7800 Hz). Files that are higher or lower sampling rate than 16 kHz will be up- or down-sampled by default to 16 kHz during the feature generation procedure, which may produce artifacts for upsampled files. You can modify this default sample rate as part of configuring features (see Feature Configuration for more details).
Bit depth#
Kaldi can only process 16-bit WAV files. Higher bit depths (24 and 32 bit) are getting more common for recording, so MFA will automatically convert higher bit depths via sox or ffmpeg.
Duration#
In general, audio segments (sound files for Prosodylab-aligner format or intervals for the TextGrid format) should be less than 30 seconds for best performance (the shorter the faster). We recommend using breaks like breaths or silent pauses (i.e., not associated with a stop closure) to separate the audio segments. For longer segments, setting the beam and retry beam higher than their defaults will allow them to be aligned. The default beam/retry beam is very conservative 10/40, so something like 400/1000 will allow for much longer sequences to be aligned. Though also note that the higher the beam value, the slower alignment will be as well. See Global Options for more details.